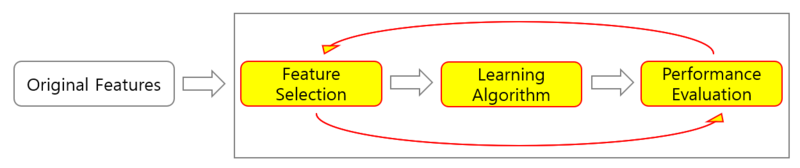
Feature Selection (특성 선택) 이란 가지고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택하는 것을 말한다.
Feature Selection 과 Feature Extraction 은 다르다.
Feature Selection 이 변수 A, B, C, D 중 모델이 분류하는데 가장 중요하게 사용한 변수 B, C라는 조합을 찾아내는 것이라면, Feature Extraction 은 모든 변수를 조합하여 데이터를 잘 표현할 수 있는 새로운 변수를 추출한다. 예를 들어 A, B, C, D 변수를 조합하여 a, b, c, d라는 새로운 변수를 추출한다
즉, 모델의 분류 정확도를 향상시키기 위해, 원본 데이터에서 가장 좋은 성능을 보여불 수 있는 데이터의 부분집합(Subset)을 찾아내는 방법이라는 점에서 같다.
Feature Selection 을 사용한다면 분류 목적과 가장 밀접하게 연관되어 있는 특징만을 사용하게 됨으로 모델의 성능의 향상을 기대할 수 있으며, 또한 처리할 데이터의 양이 줄어듦으로 처리 속도 또한 빨라지게 된다.
Feature Selection Algorithms에는 크게 세 가지가 있다 : Filter Methods , Wrapper Methods, Embeded Methods
1) Filter Methods
: 모델에 적용하기 전에 Feature들을 걸러내는 방법으로 전처리 과정이라 볼 수 있다. 통계적인 계산에 의해 영향력을 바탕으로 각 Feature 들을 랭킹화한 뒤 랭킹에 따라 데이터 셋에서 그대로 남아있거나 제거되게 된다.
피어슨 상관분석, 카이제곱검정 등을 사용하여 상관관계를 파악한다.


2) Wrapper Methods
: 가장 이상적인 Feature의 조합을 찾는 방식으로, Feature 을 다르게 조합하여 모델 학습을 진행하는 것을 말한다. 최종적으로 모델 중 점수가 가장 성능이 좋은(정확도 or AUC 등등) 모델을 선택한 뒤 해당 모델이 사용한 Feature의 조합을 확인한다면, 가장 높은 정확도(본인이 만약 정확도라고 설정했다면)를 보이는 Feature들의 조합을 얻을 수 있다.
조합을 제작하는 방법으로 Forward Selction, Backward Elimination, Stepwise Selection 등이 있다.


3) Embeded Methods
: 모델의 학습 및 생성 과정에서 최적의 Feature를 선택한다. 대표적으로 LASSO 와 Ridge Regression 이 있다.
출처 : m.blog.naver.com/euleekwon/221464171572
[머신러닝] Basic Knowledge of Feature Selection
프로그래밍 1학년 수업 때 가장 많이 듣는 말이 하나 있었다. GIGO. Garbage In Garbate Out..어떤...
blog.naver.com
'머신러닝&딥러닝' 카테고리의 다른 글
| Numpy 기본 함수/연산자 (0) | 2021.02.14 |
|---|---|
| Numpy 와 Pandas는 다르다. (0) | 2021.01.27 |
| 파라미터 vs 하이퍼파라미터 (0) | 2021.01.19 |
| 노이즈 데이터 (Nosiy Data) (0) | 2021.01.17 |

