BeautifulSoup은 HTML 문서를 예쁘게 정돈된 파스트리로 변환하여 내놓는 파이썬 라이브러리다. 이 잘 정돈된 데이터 구조는 Beautiful Soup 객체로서 여러 tag 객체로 이루어져 있다. 영어, 한국어와 같은 자연어 문장이 문법에 따라 구조를 갖듯이 HTML 이라는 웹을 이루는 언어로 작성된 페이지를 문법에 맞게 구조화한다.

find 와 select 는 BeautifulSoup의 메소드로서 데이터 구조를 항해하는 몇 가지 방법이다.
01. find 사용법

find의 목적은 원하는 태그를 찾는 것이다. 태그는 이름(name), 속성(attribute), 속성값(value)로 구성된다. 따라서 find로 이름, 속성, 속성값을 특정하여 태그를 찾을 수 있다.
tag = "<p class='youngone' id='junu'> Hello World! </p>"
soup = BeautifulSoup(tag)
# 태그 이름만 특정
soup.find('p')
# 태그 속성만 특정
soup.find(class_='youngone')
soup.find(attrs = {'class':'youngone'})
# 태그 이름과 속성 모두 특정
soup.find('p', class_='youngone')
BeautifulSoup을 이용하여 태그를 찾고 이를 tag 객체에 담아 반환한다. tag 객체는 태그의 요소를 자신의 속성으로 갖는다.
tag = "<p class='youngone' id='junu'> Hello World! </p>"
soup = BeautifulSoup(tag)
object_tag = soup.find('p')
#태그의 이름
object_tag.name
#결과: 'p'
#태그에 담긴 텍스트
object_tag.text
#결과: ' Hello World! '
#태그의 속성과 속성값
object_tag.attrs
#결과: {'class': ['youngone'], 'id': 'junu'}
02. select 사용법
select는 CSS selector로 tag 객체를 찾아 반환한다. 이는 CSS에서 HTML을 태깅하는 방법을 활용한 메소드다. 가장 첫 번째 결과를 반환하는 select_one()은 find()에, 전체 결과를 리스트로 반환하는 select()는 find_all()에 대응한다.
# 태그 이름만 특정
soup.select_one('p')
# 태그 class 특정
soup.select_one('.youngone')
# 태그 이름과 class 모두 특정
soup.select_one('p.youngone')
# 태그 id 특정
soup.select_one('#junu')
# 태그 이름과 id 모두 특정
soup.select_one('p#junu')
# 태그 이름과 class, id 모두 특정
soup.select_one('p.youngone#junu')
find처럼 태그 이름, 속성, 속성값을 특정하는 방식은 같다. 하지만 CSS는 이 외에도 다양한 선택자(selector)를 갖기 때문에 여러 요소를 조합하여 태그를 특정하기 쉽다. 예를 들어 특정 경로의 태그를 객체로 반환하고 싶을 때, find의 경우 반복적으로 코드를 작성해야 한다. select는 직접 하위 경로를 지정할 수 있기 때문에 간편하다.
#find
soup.find('div').find('p')
#select
soup.select_one('div > p')
결론적으로 select를 사용하는 게 정신건강에 이롭다. 더 다양한 조건으로, 더 직관적인 방법으로 태그를 쫓을 수 있기 때문이다. 게다가 select가 수행시간도 더 빠르며 메모리 소모량도 더 적다.
03. find에서 select로 syntax에서 semantics으로
인터넷이 발전하면서 웹의 복잡도는 기하급수적으로 올라갔다. 웹문서의 구조를 이루는 HTML에 디자인의 CSS, 움직임의 JavaScript까지 더해졌기 때문이다. 웹은 이제 깔끔한 파스 트리로 후루룩 정리하기에는 너무 복잡해졌다.
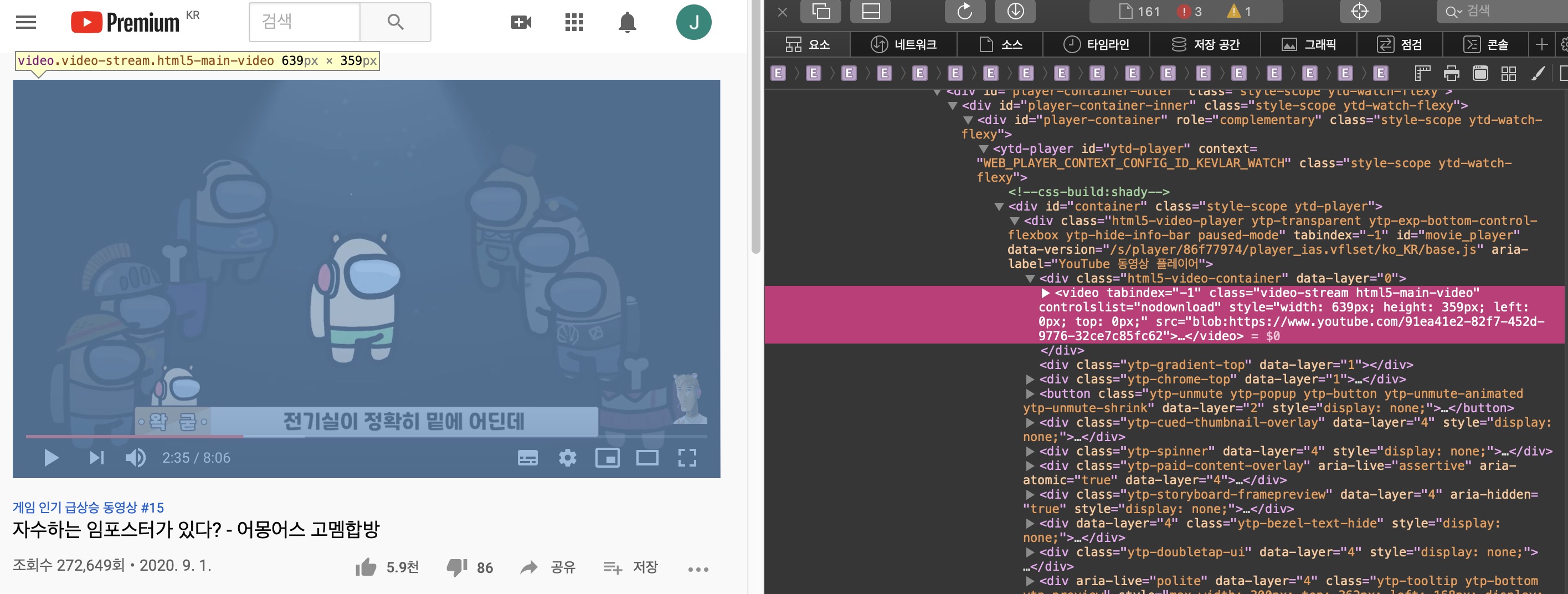
한 태그에 걸려있는 수많은 속성과 속성값들...
웹의 복잡성에 대응하기 위해 오히려 HTML은 자유도를 높였다. 2014년 웹 표준으로 선정된 HTML5의 모토는 '더 간단하게, 더 자유롭게'다. 불필요한 규칙을 줄이고 데이터형식의 다양한 태그를 추가했다. 높아진 자유도는 웹이 플랫폼으로서 제대로 활동할 수 있는 무대를 만들었다. 더이상 웹은 인터넷에 존재하는 문서의 집합이 아니다.
select 메소드는 이러한 웹의 발전에 맥락을 같이 한다. select도 2014년에 BeautifulSoup에 추가됐다. find는 tag를 웹의 구조 안에서 파악하는 것이 목적:syntax이다. 반면 select는 tag가 갖는 속성을 기준으로 역할에 따라 태그를 정의하는 것:semantics이 목적이다. 엄격한 규칙에 따른 구조보다 속성과 역할에 따른 관계망으로 웹을 바라본다. 이는 파이썬과 같은 객체 지향 언어가 추구하는 바와 같다.

semantic
04. Beautiful Soup의 뜻
라이브러리 Beautiful Soup의 이름은 tag soup에서 유래한다. tag soup이란 문법, 구조적으로 잘못된 HTML 웹 문서를 일컫는 용어다. HTML 문서는 오류에 유연하게 대응할 수 있기에 웹 개발자들이 엄격하게 규칙을 따르지 않는 경우가 많았다. HTML과 텍스트가 마구잡이로 뒤섞이고 닫는 태그도 제대로 지켜지지 않을 때도 있었다. 이런 더러운 구조를 가진 웹문서를 두고 마구 뒤섞인 수프와 같다고 해서 tag soup란 이름이 붙었다.

BeautifulSoup은 tag soup을 아름답게 변환시켜준다는 의미에서 지은 이름이다. 이는 동화 '이상한 나라의 앨리스'에서도 등장한다. 앨리스는 가짜 거북과 함께 시를 외우다 지쳐버린다. 뒤죽박죽이고 말이 안맞는 부분이 너무 많기 때문이다. 그래서 가짜 거북에게 차라리 노래를 한 곡 불러달라고 부탁한다. 가짜 거북은 '거북 수프'라는 노래를 부른다.
"이걸 다 외워서 무슨 소용이야!"
가짜 거북이가 또 끼어들며 말했어요.
"추가 설명 없인 대체 무슨 소린지 하나도 모르겠구나. 내 생전 이렇게 헷갈리는 시는 또 처음이야."
가짜 거북이는 깊은 한 숨을 몰아쉬더니 이따금씩 흐느낌을 삼키는 목소리로 다음과 같은 노래를 부르기 시작했어요.
"아름다운 수프, 풍만한 녹색,
그릇에서 기다리거라!
누가 이 맛있는 것에 숙이지 않으리?
저녁 수프, 아름다운 수프!
아--르음다운 수---프!
저어녀---엌 수---프!
아름다운, 아름다운 수프
프로그래밍에서 과거의 아름다움이 보기 좋게 정렬된 구조였다면, 현재의 아름다움은 더 복잡하게 연결된 구조에서 발견하는 자유로움이 아닐까.
출처: https://desarraigado.tistory.com/14
BeautifulSoup 모듈 find와 select의 차이점 - 복잡한 웹을 간단하게
BeautifulSoup은 HTML 문서를 예쁘게 정돈된 파스트리로 변환하여 내놓는 파이썬 라이브러리다. 이 잘 정돈된 데이터 구조는 Beautiful Soup 객체로서 여러 tag 객체로 이루어져 있다. 영어, 한국어와 같은
desarraigado.tistory.com
'컴퓨팅' 카테고리의 다른 글
| HTML 입문 (0) | 2020.12.24 |
|---|---|
| URL 이해 (0) | 2020.12.24 |
| Python_jupyter 줄바꿈 (0) | 2020.12.23 |
| HTML 과 XML의 차이 (0) | 2020.12.23 |
| 파일 다운로드 버튼 url 알아내기_http trace (0) | 2020.12.23 |

