1. countplot
: 범주형 데이터 일때, label값에 따라 카운트 해줄 때 유용하다.
- 칼럼을 구성하고 있는 값(value)에 따라 갯수카운트를 해준다.
- 'hue= 칼럼' 파라미터로 target변수에 따라 카운팅 해주는 것도 매우 유용하다.
sns.countplot(x='Census_ProcessorClass', hue='HasDetections',data=train_small)
plt.show()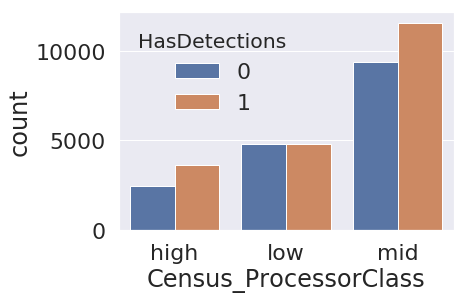
2. distplot
: 연속형 변수일 때, 값의 분포를 확인할 때 유용하다.
- 'bin = 숫자 ' 파라미터로 히스토그램 구간 값을 줄일 수 있다.
- matplotlitb에서 hist 그래프와 kdeplot(확률밀도함수)을 통합한 그래프라고 한다.
- 'vertical = 논리' 파라미터로 가로 세로 역전시킬 수 있다.
plt.figure(figsize=(9, 8))
sns.distplot(df['SalePrice'], color='g', bins=100, hist_kws={'alpha': 0.4});
3. heatmap
- 칼럼별로 공분산 값을 계산한 뒤, 색밀도로 시각화 할 때 유용하다.
(원래는 데이터셋을 색밀도로 표현하는 그래프인데, 공분산 데이터셋으로 자주 이용한다.)
- 공분산을 계산하기 때문에 str 형태로 되어 있는 범주형 칼럼일 경우 그래프에서 제외된다.
- 'annot=논리'로 공분산 값을 표시해줄 수 있음
- 'cmap=테마명'으로 색 컬러 테마 지정 가능
corr = df_num.drop('SalePrice', axis=1).corr() # We already examined SalePrice correlations
plt.figure(figsize=(12, 10))
sns.heatmap(corr[(corr >= 0.5) | (corr <= -0.4)],
cmap='viridis', vmax=1.0, vmin=-1.0, linewidths=0.1,
annot=True, annot_kws={"size": 8}, square=True);

상관계수는 일반적으로
값이 -1.0 ~ -0.7 이면, 강한 음적 상관관계
값이 -0.7 ~ -0.3 이면, 뚜렷한 음적 상관관계
값이 -0.3 ~ -0.1 이면, 약한 음적 상관관계
값이 -0.1 ~ +0.1 이면, 없다고 할 수 있는 상관관계
값이 +0.1 ~ +0.3 이면, 약한 양적 상관관계
값이 +0.3 ~ +0.7 이면, 뚜렷한 양적 상관관계
값이 +0.7 ~ +1.0 이면, 강한 양적 상관관계
4. pairplot
: 숫자형 데이터셋에서 칼럼별 상관관계를 한번에 시각화하고 싶을 때 유용하다.
- 상관관계 표현 시, 자기 자신에 대해서는 히스토그램으로 표현되고, 매칭 칼럼은 산점도로 표현
- 'hue=칼럼' 으로 타겟 칼럼에 따라 다른 색으로 구분 지을 수 있다.
- 'palette=팔렛트명'으로 컬러테마 적용
- 'vars=[ 칼럼1, 칼럼2..]' 파라미터로 특정 칼럼과의 매칭만 시각화 가능
for i in range(0, len(df_num.columns), 5):
sns.pairplot(data=df_num,
x_vars=df_num.columns[i:i+5],
y_vars=['SalePrice'])
break; #전체 데이터셋 사이클 돌리지 않고 5개씩 한 사이클 보여주고 스톱
5. lmplot , regplot
- 상관관계를 산점도와 회귀선으로 시각화할 때 유용하다.
- 회귀선은 그려진 뒤 95% 신뢰구간을 표시해준다.
*implot은 여러가지 시각화옵션이 다양하다.
- lmplot은 'hue=칼럼'으로 색을 구분지을 수 있고 , marker=["o","x"] 로 표시방법도 구분할 수 있다.
- 'palette=팔렛트명'으로 색 테마 지정 가능하다.
- 'col=칼럼' 으로 특정 칼럼의 값에 따라 회귀선을 구분지어 그릴 수도 있다.
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
markers=["o", "x"], palette="Set1", col="time")
fig, ax = plt.subplots(round(len(features_to_analyse) / 3), 3, figsize = (18, 12))
for i, ax in enumerate(fig.axes):
if i < len(features_to_analyse) - 1:
sns.regplot(x=features_to_analyse[i],y='SalePrice', data=df[features_to_analyse], ax=ax)
6. boxplot
: 데이터를 4분위 분포 값에 따라 시각화하고 싶을 때 유용하다.
- 범주형 데이터인 특정 칼럼에서 라벨링 값에 따라 분포를 확인하는데 잘 사용된다.
plt.figure(figsize = (12, 6))
ax = sns.boxplot(x='SaleCondition', y='SalePrice', data=df_categ)
plt.setp(ax.artists, alpha=.5, linewidth=2, edgecolor="k") #그림 객체별로 step해서 옵션지정
plt.xticks(rotation=45) #글자 기울이기
그래프 해석방법 matplotlib에 대한 이해 자체를 높이는 글


7. violinplot
: boxplot과 마찬가지로 4분위 분포 값에 따라 데이터를 시각화 하는데 좋다
- 범주형 데이터인 특정 칼럼에서 라벨링 값에 따라 분포를 확인하는데 잘 사용된다.
- boxplot에 추가기능이 있다; 데이터 값 표시 뿐만 아니라, 데이터 자체의 분포도 시각화 되어 나타난다.
plt.style.use('seaborn')
plt.figure(figsize = (12, 6))
ax = sns.violinplot(x='SaleCondition', y='SalePrice', data=df_categ)
plt.setp(ax.artists, alpha=.5, linewidth=2, edgecolor="k")
plt.xticks(rotation=45)
바이올린 그래프 해석방법
- 중심선을 따라 대칭인 KDE 플롯이 있다.
- 가운데 흰색 점은 중앙값(median)을 나타낸다.
- 바이올린 중앙의 두꺼운 선은 사분위 범위를 나타낸다.
- 바이올린 중앙의 얇은 선은 신뢰 구간을 나타낸다. (bar plot과 마찬가지로 95% 신뢰 구간이 표시된다.)
8. stripplot
: barplot 혹은 violinplot의 형태이나 scatterplot처럼 점 형태로 데이터를 표시한다.
- 'jitter=True' 로 설정하면 가로축 상의 위치를 무작위로 바꾸어 데이터 수가 많을 경우 겹치지 않게 한다.
np.random.seed(0)
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True)
plt.title("요일 별 전체 팁의 Strip Plot")
plt.show()
9. kdeplot
: 확률밀도함수로 데이터의 밀도를 확인할 때 유용하다.
-숫자 데이터만 가능하다.
-'shade =논리' 그래프 음영표시
-'shade_lowest = 논리' 옵션은 잘 모르겠다. False로 표시해야 탈이 없음..(default =False임)
fig, ax = plt.subplots(1, 2, figsize = (8, 6))
#graph1
sns.kdeplot(setosa.sepal_width, shade=True, shade_lowest=False,ax=ax[0])
#graph2
sns.kdeplot(setosa.sepal_width, setosa.sepal_length, cmap="Reds", shade=True,
shade_lowest=False, ax=ax[1])
sns.kdeplot(virginica.sepal_width, virginica.sepal_length, cmap="Blues", shade=True,
shade_lowest=False,ax=ax[1])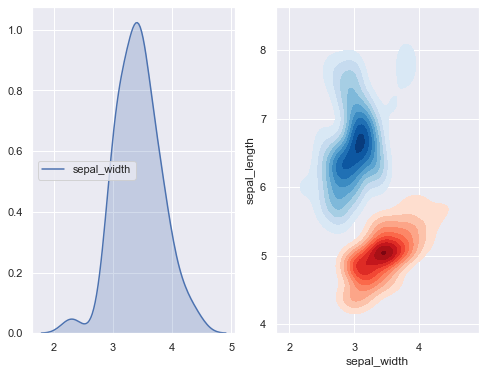
10. jointplot
: 산점도와 히스토그램을 동시에 그려준다.
- 숫자 데이터만 가능하다.
- 'kind=종류' 옵션으로 그래프 종류를 변경할 수 있다. (회귀선 밀도함수 등)
sns.jointplot(x="sepal_length", y="sepal_width", data=iris, kind='regression')
plt.suptitle("regression Joint Plot", y=1.02)
plt.show()
출처1. data101.oopy.io/b77f0e91-6d16-42cb-b4c7-b452aabc14da
Visualizing linear relationships
Visualizing linear relationships - seaborn 0.10.1 documentation
data101.oopy.io
Seaborn을 사용한 데이터 분포 시각화 — 데이터 사이언스 스쿨
1차원 데이터는 실수 값이면 히스토그램과 같은 실수 분포 플롯으로 나타내고 카테고리 값이면 카운트 플롯으로 나타낸다. 우선 연습을 위한 샘플 데이터를 로드한다. 1차원 실수 분포 플롯 실
datascienceschool.net
출처 3: seaborn.pydata.org/generated/seaborn.regplot.html
출처 5: www.kaggle.com/ash316/eda-to-prediction-dietanic
'데이터분석&캐글' 카테고리의 다른 글
| 데이터스케일링_로그변환 (0) | 2021.02.25 |
|---|---|
| 사람들이 선형회귀에 대해 잘못 알고있는 점 (0) | 2021.02.19 |
| 캐글코리아 커널 커리큘럼 (0) | 2021.01.20 |
| Kaggle로 알아보는 데이터 분석사고 (0) | 2021.01.20 |
| 범주형 자료 Encoding for Handling (0) | 2021.01.16 |


